Why XHTML
Thursday, June 5th, 2008Here’s part 5 of the ongoing serialization of Refactoring HTML, also available from Amazon and Safari.
XHTML is simply an XML-ized version of HTML. Whereas HTML is at least theoretically built on top of SGML, XHTML is built on top of XML. XML is a much simpler, clearer spec than SGML. Therefore, XHTML is a simpler, clearer version of HTML. However, like a gun, a lot depends on whether you’re facing its front or rear end.
XHTML makes life harder for document authors in exchange for making life easier for document consumers. Whereas HTML is forgiving, XHTML is not. In HTML, nothing too serious happens if you omit an end-tag or leave off a quote here or there. Some extra text may be marked in boldface or be improperly indented. At worst, a few words here or there may vanish. However, most of the page will still display. This forgiving nature gives HTML a very shallow learning curve. Although you can make mistakes when writing HTML, nothing horrible happens to you if you do.
By contrast, XHTML is much stricter. A trivial mistake such as a missing quote or an omitted end-tag that a browser would silently recover from in HTML becomes a four-alarm, drop-everything, sirens-blaring emergency in XHTML. One little, tiny error in an XHTML document, and the browser will throw up its hands and refuse to display the page, as shown in Figure 1.2. This makes writing XHTML pages harder, especially if you’re using a plain text editor. Like writing a computer program, one syntax error breaks everything. There is no leeway, and no margin for error.
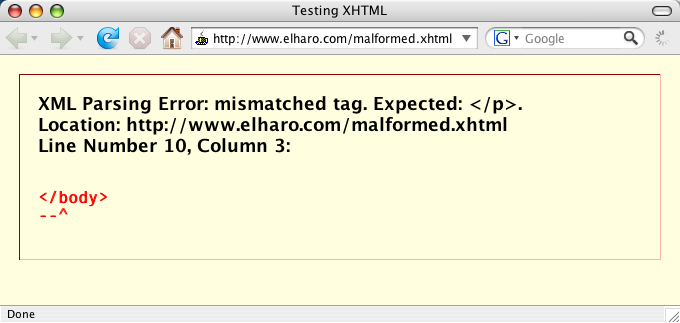
Figure 1.2: Firefox responding to an error in an XHTML page
Why, then, would anybody choose XHTML? Because the same characteristics that make authoring XHTML a challenge (draconian error handling) make consuming XHTML a walk in the park. Work has been shifted from the browser to the author. A web browser (or anything else that reads the page) doesn’t have to try to make sense out of a confusing mess of tag soup and guess what the page really meant to say. If the page is unclear in any way, the browser is allowed, in fact required, to throw up its hands and refuse to process it. This makes the browser’s job much simpler. A large portion of today’s browsers devote a large chunk of their HTML parsing code simply to correcting errors in pages. With XHTML they don’t have to do that.
