Validators
Here’s part 10 of the ongoing serialization of Refactoring HTML, also available from Amazon and Safari.
There really are standards for HTML, even if nobody follows them. One way to find out whether a site follows HTML standards is to run a page through a validation service. The results can be enlightening. They will provide you with specific details to fix, as well as a good idea of how much work you have ahead of you.
The W3C Markup Validation Service
For public pages, the validator of choice is the W3C’s Markup Validation Service, at http://validator.w3.org/. Simply enter the URL of the page you wish to check, and see what it tells you. For example, Figure 2.1 shows the result of validating my blog against this service.
Figure 2.1: The W3C Markup Validation Service
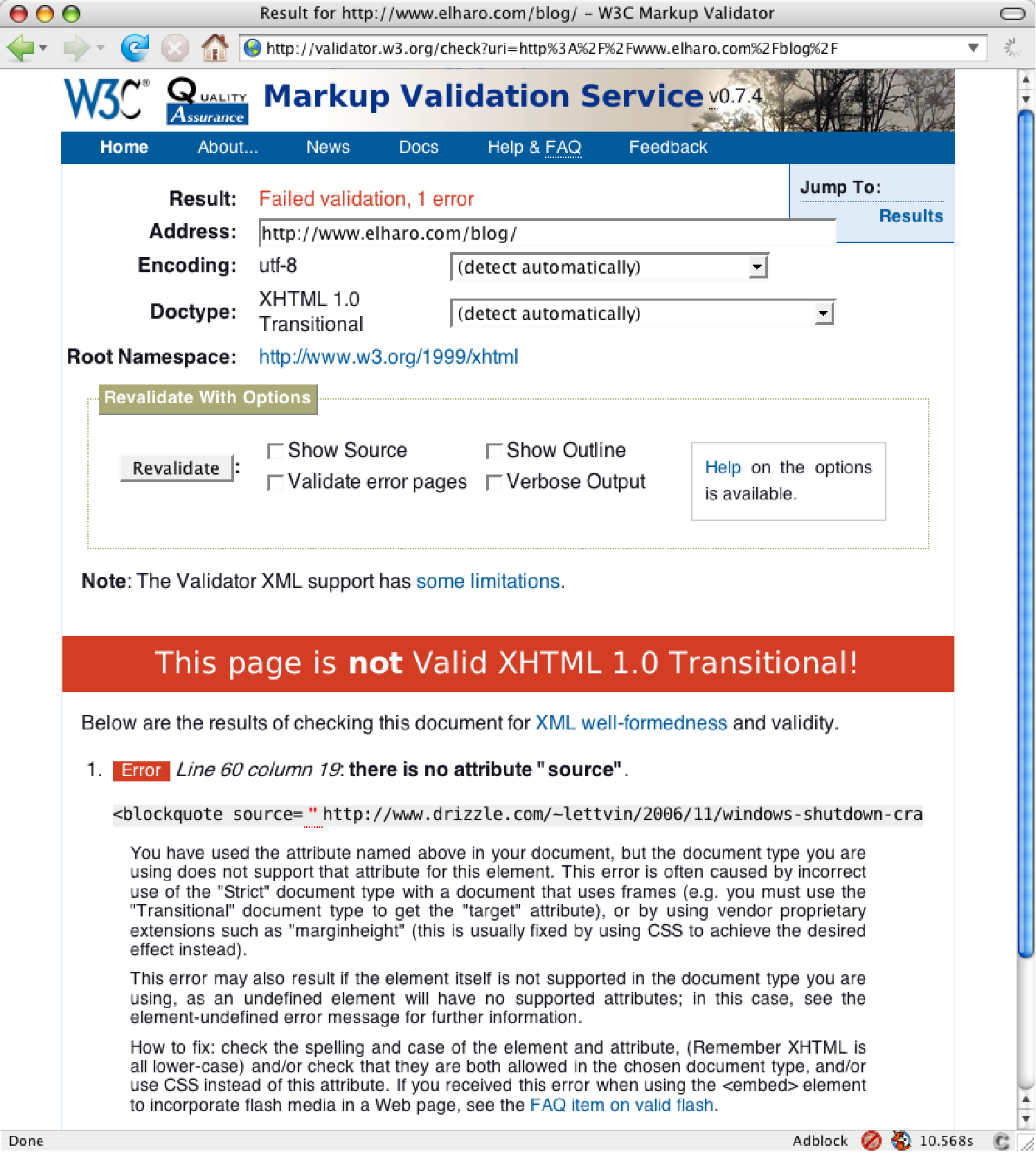
It seems I had misremembered the syntax of the blockquote element. I had mistyped the cite attribute as the source attribute. This was actually better than I expected. I fixed that and rechecked, as shown in Figure 2.2. Now the page is valid.
Figure 2.2: Desired results: a valid page

It is usually not necessary to check each and every page on your site for these sorts of errors. Most errors repeat themselves. Generally, once you identify a class of errors, it becomes possible to find and automatically fix the problems. For example, here I could simply search for <blockquote source=" to find other places where I had made the same mistake.
This page was actually cleaner than normal to begin with. I next tried one of the oldest and least maintained pages I could find on my sites. This generated 144 different errors.
Private Validation
The W3C is reasonably trustworthy. Still, you may not want to submit private pages from your intranet to the site. Indeed, for people dealing with medical, financial, and other personal data, it may be illegal to do so. You can download a copy of the HTML validator scripts from http://validator.w3.org/docs/install and install them locally. Then your pages don’t need to travel outside your firewall when validating.
This style of validation is good when authoring. It is also extremely useful for spot-checking a site to see how much work you’re likely to do, or for working on a single page. However, at some point, you’ll want to verify all of the pages on a site, not just a few of them. For this, an automatic batch validator is a necessity.
The Log Validator
The W3C Markup Validation Service has given birth to the Log Validator (http://www.w3.org/QA/Tools/LogValidator/), a command-line tool written in Perl that can check an entire site. It can also use a web server’s log files to determine which pages are the most popular and start its analysis there. Obviously, you care a lot more about fixing the page that gets 100 hits a minute than the one that gets 100 hits a year. The Log Validator will provide you with a convenient list of problems to fix, prioritized by seriousness and popularity of page. Listing 2.1 shows the beginning of one such list.
Listing 2.1: Log Validator Output
Results for module HTMLValidator **************************************************************** Here are the 10 most popular invalid document(s) that I could find in the logs for www.elharo.com. Rank Hits #Error(s) Address ------ ------ ----------- ------------------------------------- 1 2738 21 http://www.elharo.com/blog/feed/atom/ 2 1355 21 http://www.elharo.com/blog/feed/ 3 1231 3 http://www.elharo.com/blog/ 4 1127 6 http://www.elharo.com/ 6 738 3 http://www.elharo.com/blog/networks/2006/03/18/looking-for-a-router/feed/ 11 530 3 http://www.elharo.com/journal/fruitopia.html 20 340 1 http://www.elharo.com/blog/wp-comments-post.php 23 305 3 http://www.elharo.com/blog/birding/2006/03/15/birding-at-sd/ 25 290 4 http://www.elharo.com/journal/fasttimes.html 26 274 1 http://www.elharo.com/journal/
The first two pages in this list are Atom feed documents, not HTML files at all. Thus, it’s no surprise that they show up as invalid. The third and fourth ones are embarrassing, though, since they’re my blog’s main page and my home page, respectively. They’re definitely worth fixing. The fifth most visited page on my site is valid, however, so it doesn’t show up in the list. Numbers 11, 25, and 26 are very old pages that predate XML, much less XHTML. It’s no surprise that they’re invalid; but because they’re still getting hits, it’s worth fixing them.
Number 20 is also a false positive. That’s just the comments script used to post comments. When the validator tries to GET it rather than POST to it, it receives a blank page. That’s not a real problem, though I might want to fix it one of these days to show a complete list of the comments. Or perhaps I should simply set up the script to return “HTTP error 405 Method Not Allowed” rather than replying with “200 OK” and a blank document.
After these, various other pages that aren’t as popular are listed. Just start at the top and work your way down.
xmllint
You can also use a generic XML validator such as xmllint, which is bundled on many UNIX machines and is also available for Windows. It is part of libxml2, which you can download from http://xmlsoft.org/.
There are advantages and disadvantages to using a generic XML validator to check HTML. One advantage is that you can separate well-formedness checking from validity checking. It is usually easier to fix well-formedness problems first, and then fix validity problems. Indeed, that is the order in which this book is organized. Well-formedness is also more important than validity.
The first disadvantage of using a generic XML validator is that it won’t catch HTML-specific problems that are not specifically spelled out in the DTD. For instance, it won’t notice an a element nested inside another a element (though that problem doesn’t come up a lot in practice). The second disadvantage is that it will have to actually read the DTD. It doesn’t assume anything about the document it’s checking.
Using xmllint to check for well-formedness is straightforward. Just point it at the local file or remote URL you wish to check from the command line. Use the –noout option to say that the document itself shouldn’t be printed, and –loaddtd to allow entity references to be resolved. For example:
$ xmllint --noout --loaddtd http://www.aw.com http://www.aw-bc.com/:118: parser error : Specification mandate value for attribute nowrap <TD class="headerBg" bgcolor="#004F99" nowrap align="left"> ^ http://www.aw-bc.com/:118: parser error : attributes construct error <TD class="headerBg" bgcolor="#004F99" nowrap align="left"> ^ http://www.aw-bc.com/:118: parser error : Couldn't find end of Start Tag TD line 118 <TD class="headerBg" bgcolor="#004F99" nowrap align="left"> ^ http://www.aw-bc.com/:120: parser error : Opening and ending tag mismatch: IMG line 120 and A Benjamin Cummings" WIDTH="84" HEIGHT="64" HSPACE="0" VSPACE="0" BORDER="0"></A> …
When you first run a report such as this, the number of error messages can be daunting. Don’t despair—start at the top and fix the problems one by one. Most errors fall into certain common categories which we will discuss later in the book, and you can fix them en masse. For instance, in this example, the first error is a valueless nowrap attribute. You can fix this simply by searching for nowrap and replacing it with nowrap=”nowrap”. Indeed, with a multifile search and replace, you can fix this problem on an entire site in less than five minutes. (I’ll get to the details of that a little later in this chapter.)
The next problem is an IMG element that uses a start-tag rather than an empty-element tag. This one isn’t quite as easy, but you can fix most occurrences by searching for BORDER="0"> and replacing it with border="0" />. That won’t catch all of the problems with IMG elements, but it will fix a lot of them.
After each change, you run the validator again. You should see fewer problems with each pass, though occasionally a new one will crop up. Simply iterate and repeat the process until there are no more well-formedness errors.
It is important to start with the first error in the list, though, and not pick an error randomly. Often, one early mistake can cause multiple well-formedness problems. This is especially true for omitted start-tags and end-tags. Fixing an early problem often removes the need to fix many later ones.
Once you have achieved well-formedness, the next step is to check validity. You simply add the --valid switch on the command line, like so:
$ xmllint –noout –loaddtd –valid valid_aw.html
This will likely produce many more errors to inspect and fix, though these are usually not as critical or problematic. The basic approach is the same, though: Start at the beginning and work your way through until all the problems are solved.
Editors
Many HTML editors have built-in support for validating pages. For example, in BBEdit you can just go to the Markup menu and select Check/Document Syntax to validate the page you’re editing. In Dreamweaver, you can use the context menu that offers a Validate Current Document item. (Just make sure the validator settings indicate XHTML rather than HTML.) In essence, these tools just run the document through a parser such as xmllint to see whether it’s error-free.
If you’re using Firefox, you should install Chris Pederick’s Web Developer plug-in (https://addons.mozilla.org/firefox/60/). Once you’ve done that, you can validate any page by going to Tools/Web Developer/Tools/Validate HTML. This loads the current page in the W3C validator. The plug-in also provides a lot of other useful options in Firefox.
Whatever tool or technique you use to find the markup mistakes, validating is the first step to refactoring into XHTML. Once you see what the problems are, you’re halfway to fixing them.
Continued tomorrow…
