Why XHTML
Here’s part 5 of the ongoing serialization of Refactoring HTML, also available from Amazon and Safari.
XHTML is simply an XML-ized version of HTML. Whereas HTML is at least theoretically built on top of SGML, XHTML is built on top of XML. XML is a much simpler, clearer spec than SGML. Therefore, XHTML is a simpler, clearer version of HTML. However, like a gun, a lot depends on whether you’re facing its front or rear end.
XHTML makes life harder for document authors in exchange for making life easier for document consumers. Whereas HTML is forgiving, XHTML is not. In HTML, nothing too serious happens if you omit an end-tag or leave off a quote here or there. Some extra text may be marked in boldface or be improperly indented. At worst, a few words here or there may vanish. However, most of the page will still display. This forgiving nature gives HTML a very shallow learning curve. Although you can make mistakes when writing HTML, nothing horrible happens to you if you do.
By contrast, XHTML is much stricter. A trivial mistake such as a missing quote or an omitted end-tag that a browser would silently recover from in HTML becomes a four-alarm, drop-everything, sirens-blaring emergency in XHTML. One little, tiny error in an XHTML document, and the browser will throw up its hands and refuse to display the page, as shown in Figure 1.2. This makes writing XHTML pages harder, especially if you’re using a plain text editor. Like writing a computer program, one syntax error breaks everything. There is no leeway, and no margin for error.
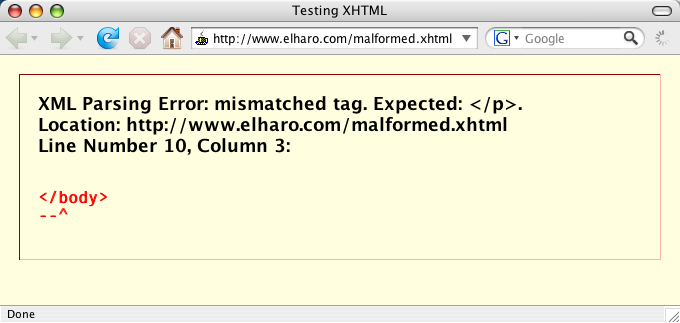
Figure 1.2: Firefox responding to an error in an XHTML page
Why, then, would anybody choose XHTML? Because the same characteristics that make authoring XHTML a challenge (draconian error handling) make consuming XHTML a walk in the park. Work has been shifted from the browser to the author. A web browser (or anything else that reads the page) doesn’t have to try to make sense out of a confusing mess of tag soup and guess what the page really meant to say. If the page is unclear in any way, the browser is allowed, in fact required, to throw up its hands and refuse to process it. This makes the browser’s job much simpler. A large portion of today’s browsers devote a large chunk of their HTML parsing code simply to correcting errors in pages. With XHTML they don’t have to do that.
Of course, most of us are not browser vendors and are never going to write a browser. What do we gain from XHTML and its draconian error handling? There are several benefits. First of all, though most of us will never write a browser, many of us do write programs that consume web pages. These can be mashups, web spiders, blog aggregators, search engines, authoring tools, and a dozen other things that all need to read web pages. These programs are much easier to write when the data you’re processing is XHTML rather than HTML.
Of course, many people working on the Web and most people authoring for the Web are not classic programmers and are not going to write a web spider or a blog aggregator. However, there are two things they are very likely to write: JavaScript and stylesheets. By number, these are by far the most common kinds of programs that read web pages. Every JavaScript program embedded in a web page itself reads the web page. Every CSS stylesheet (though perhaps not a program in the traditional sense of the word) also reads the web page. JavaScript and CSS are much easier to write and debug when the pages they operate on are XHTML rather than HTML. In fact, the extra cost of making a page valid XHTML is more than paid back by the time you save debugging your JavaScript and CSS.
While fixing XHTML errors is annoying and takes some time, it’s a fairly straightforward process and not all that hard to do. A validator will list the errors. Then you go through the list and fix each one. In fact, errors at this level are fairly predictable and can often be fixed automatically, as we’ll see in Chapters 3 and 4. You usually don’t need to fix each problem by hand. Repairing XHTML can take a little time, but the amount of time is predictable. It doesn’t become the sort of indefinite time sink you encounter when debugging cross-browser JavaScript or CSS interactions with ill-formed HTML.
Writing correct XHTML is only even mildly challenging when hand authoring in a text editor. If tools generate your markup, XHTML becomes a no-brainer. Good WYSIWYG HTML editors such as Dreamweaver 8 can (and should) be configured to produce valid XHTML by default. Markup level editors such as BBEdit can also be set to use XHTML rules, though authors will need to be a little more careful here. Many have options to check a document for XHTML validity and can even automatically correct any errors with the click of a button. Make sure you have turned on the necessary preference in your editor of choice. Similarly good CMSs, Wikis, and blog engines can all be told to generate XHTML. If your authoring tool does not support XHTML, by all means get a better tool. In 2008, there’s no excuse for an HTML editor or web publishing system not to support XHTML.
If your site is using a hand-grown templating system, you may have a little more work to do; and you’ll see exactly what you need to do in Chapters 3 and 4. Although the process here is a little more manual, once you’ve made the changes, valid XHTML falls out automatically. Authors entering content through databases or web forms may not need to change their workflow at all, especially if they’re already entering data in a non-HTML format such as markdown or wikitext. The system can make the transition to XHTML transparent and painless.
The second reason to prefer XHTML over HTML is cross-browser compatibility. In practice, XHTML is much more consistent in today’s browsers than HTML. This is especially true for complex pages that make heavy use of CSS for styling or JavaScript for behavior. Although browsers can fix markup mistakes in classic HTML, they don’t always fix them the same way. Two browsers can read the same page and produce very different internal models of it. This makes writing one stylesheet or script that works across browsers a challenge. By contrast, XHTML doesn’t leave nearly so much to browser interpretation. There’s less room for browser flakiness. Although it’s certainly true that browsers differ in their level of support for all of CSS, and that their JavaScript dialects and internal DOMs are not fully compatible, moving to XHTML does remove at least one major cause of cross-browser issues. It’s not a complete solution, but it does fix a lot.
The third reason to prefer XHTML over HTML is to enable you to incorporate new technologies in your pages in the future. For reasons already elaborated upon, XHTML is a much stronger platform to build on. HTML is great for displaying text and pictures, and it’s not bad for simple forms. However, beyond that the browser becomes primarily a host for other technologies such as Flash, Java, and AJAX. There are many things the browser cannot easily do, such as math and music notation. There are other things that are much harder to do than they should be, such as alerting the user when they type an incorrect value in a form field.
Technologies exist to improve this and more are under development. These include MathML for equations, MusicXML for scores, Scalable Vector Graphics (SVG) for animated pictures, XForms for very powerful client-side applications, and more. All of these start from the foundation of XHTML. None of them operates properly with classic HTML. Refactoring your pages into XHTML will enable you to take advantage of these and other exciting new technologies going forward. In some cases, they’ll let you do things you can’t already do. In other cases, they’ll let you do things you are doing now, but much more quickly and cheaply. Either way, they’re well worth the cost of refactoring to XHTML.
Continued tomorrow…

June 5th, 2008 at 10:50 am
Another use of XHTML is if you want to pass fragments of a web page into an XSL transform.
June 5th, 2008 at 4:09 pm
What about HTML 5, which seems to be progressing at a much faster pace and is (at least) planned to include a large number of new tags and extensions for new technologies? I used code all pages valid XHTML strict but have since switched back to HTML due to lack of browser support and the more likely promise of HTML 5. The Safari developers make some great contrary arguments to using XHML to “future proof” your web pages: http://webkit.org/blog/68/understanding-html-xml-and-xhtml/.
June 5th, 2008 at 4:41 pm
Unfortunately browsers will never be able to ditch HTML parsing, due to the billions of HTML pages out there. So this perceived advantage of XHTML does not produce any practical benefit.
June 5th, 2008 at 4:58 pm
Parsing XML is not actually significantly simpler than parsing HTML, especially now that we have well-defined parsing rules. (At least, that’s what browser developers tell me, and they would presumably be in the best position to know.)
Furthermore, parsing is actually a tiny fraction of the effort that browsers have to go to to support HTML; rendering, the DOM, and so forth are much more complex and make any difference between XML parsing and HTML parsing insignificant.
Even for parsing-heavy environments (e.g. automated processing tools) we are moving to a world where both the XML parser and the HTML parser are simply off-the-shelf tools that implement the same interface, so the complexity difference isn’t so relevant anyway.
Note that XML is not a panacea that prevents syntax errors. While it does make a small set of markup errors cause fatal aborts, it leaves many more unchecked. For example, browsers won’t show error messages for incorrect values of attributes.
June 5th, 2008 at 4:58 pm
I’m sorry, but almost none of these points are relevant. If you’re trying to make a case to vendors that XHTML is better because it’s simpler, that’s not true at all. It’s just one more technology to support – HTML is never going away. However, that doesn’t matter to web developers and authors.
The problem with XHTML is that it has widely varying support among browsers, most people think they’re using it when they’re not, and it actually has subtle rendering and scripting differences from HTML. You’re only spending more time and effort by using a format that isn’t supported as well as HTML.
Furthermore, with the efforts of the WHATWG and HTML 5, error recovery is being codified in a meaningful way. It isn’t just “tag soup.” There’s rhyme and reason to what happens with malformed documents, and it’s meant to be consistent.
If you need to utilize other XML namespaces in a web document and your target audience uses browsers that support them, then XHTML is a great choice. For everything else, you’re better off using HTML.
June 5th, 2008 at 6:55 pm
@Brodie: to summarise your argument: XHTML doesn’t matter because it’s not supported, HTML5 matters even though it’s not supported.
Not sure your arguments really hold up there…
June 5th, 2008 at 10:53 pm
Many people, and especially the HTML 5 working group, keep forgetting that it’s not just about browsers. Browser vendors are not the only ones who write programs to consume web pages. They’re not even the majority of developers who write programs to consume web pages. We may now have well-defined parsing rules but we don’t yet have actual parsers that follow those rules. Maybe one day we will; maybe not. I’m not sure. But if you need to do anything with an HTML page (including your own pages) beyond throwing it in a browser window and showing it to a human user, your job will be made much simpler by choosing XHTML.
That’s still going to be true when (if) HTML 5 becomes real. The parsing rules that Ian mentions are horribly complex, very difficult to understand or implement, and pretty much impossible to follow for anyone who isn’t spending 40 hours a week on them. If we’re lucky, browser vendors may create interoperable implementations of these rules; and the rest of us can just do what we’ve always done and treat the appearance in the then-market-leading browser as the de facto standard. But if you need something better than that, then XHTML is the way to go, even for HTML 5.
June 6th, 2008 at 1:19 am
Who bloody cares?
Nobody writes their own custom XML parser. Everyone relies on one of a handful of XML parsing libraries. When decent implementations of the HTML5 parsing algorithm become available, with APIs for everyone’s favourite host language, it will be trivial to swap out the call to XML parser, and replace it by a call to the HTML5 parser.
Advantage? You’ll be able to process orders of magnitude more documents on the web.
June 6th, 2008 at 1:35 am
“The parsing rules that Ian mentions are […] pretty much impossible to follow for anyone who isn’t spending 40 hours a week on them”
That’s OK, because the people who write the browsers and parsing libraries will spend 40 hours a week on them so that the rest of us don’t have to. Implementing an XML parser from scratch isn’t trivial either, which is why most people don’t roll their own.
June 6th, 2008 at 1:41 am
Future of Web is a mobile Web. And XHTML is more fit for mobile devices’ browsers, than HTML.
HTML is very complicated and redundant. HTML code is ugly and heavy. XHTML is easy and accurate.
June 6th, 2008 at 4:24 am
FWIW, we already have HTML5 parsers in Python, Ruby, and Java. And there are projects going on for PHP, C++, and C#. (This is besides the parsers of browser engines which are also slowly being updated.)
June 6th, 2008 at 4:26 am
Igor, it shows you haven’t invested much in reading up what’s happening with mobile browsers. There’s actually very few of them which get XHTML right. Most have a forgiving HTML parser so they can render the Web. Now that we see more and more Opera and WebKit on mobile phones (and soon maybe Gecko powered too) they’ll just have the same capabilities as desktop browsers. As Ian already said, parsers are hardly the complicated bit.
June 6th, 2008 at 4:28 am
I think HTML is better because it is simpler (for humans).
However I no longer write html/xhtml, i let ruby autogenerate it whenever it is needed (and become static this way IF it is needed as well)
I understand many dont want this but I am using that approach since about 4 years, it gets better and better (while still being rather straightforward) and saves me time.
Btw Igor wrote:
“HTML code is ugly and heavy. XHTML is easy and accurate.”
This is of course false. XHTML is harder than HTML, simply because one has to go to greater lengths to ensure everything IS valid (else the page wont be displayed at all).
I think this is a fundamental weakness. Computers should try to continue rather than stopping at an error.
We dont have HTML as a programming language, so why will they stop if they find an error in .xhtml page?
June 6th, 2008 at 4:37 am
XML is an application of SGML as well as HTML is. XML is just a functionality reduced subset with some new conventions.
If you want to use XHTML you have to set the mime type of the document to xml (by requirement of the standard), if you do this, most browsers will fail to render. Therefor practically any XHTML-Page is not an standard-compliant page. Throwing an errorpage in the face of the users if there is a minor problem is not really a fault-tolerant solution, either.
June 6th, 2008 at 6:13 am
Using HTML instead of XHTML has the disadvantages of XML without the advantages. You will get tag-bloat and a format that’s not as easy to read as some others (e.g. YAML). But you won’t get truckloads of parsers in any programming language or XSLT.
I agree that XHTML development has too less momentum but going back to SGML is definitely the wrong way. Maybe I will go with the XML serialization of HTML 5 but never back to SGML.
June 6th, 2008 at 8:16 am
Of course you are aware that no version of Internet Explorer handles application/xml+xhtml as explained on the official IE Blog? And that XHTML served as text/html has exactly zero adavantage over HTML4?
June 6th, 2008 at 8:41 am
Don,
First part true (though maybe not for very much longer). Second part false. XHTML has many advantages over HTML regardless of MIME type. There’s a popular myth promulgated by that one must serve XHTML as application/xhtml+xml. That’s not at all true. text/html is just fine if it helps. The document is what it is regardless of what the MIME type says. We could serve an XHTML document as image/jpeg. That wouldn’t make it a JPEG image. Similarly, serving the document as text/html, doesn’t mean it’s not XHTML. The real decision is whether the consumer chooses to read the document as HTML or XHTML. The media type can be a useful hint to the consumer in some circumstances, but it need not control the decision absolutely.
This myth seems to be promulgated most vociferously by [^X]HTML-zealots who seek to prevent anyone from using XHTML at all. They attempt to destroy standards by insisting on mindless conformance to them, all practical experience to the contrary. My book takes a much more pragmatic approach that focuses on getting the maximum benefit at minimum cost. Serving well-formed XHTML as text/html is a solid, pragmatic action that provides real benefits to authors and document consumers who need XHTML and imposes no costs on document consumers who don’t need or care about XHTML.
June 6th, 2008 at 11:39 am
And none of this accounts for UA’s that have rendering bugs in them that don’t allow the page to display even when you’ve done perfectly fine code. Ugh.
June 7th, 2008 at 5:37 pm
Reducing the barrier to entry is extremely important in preventing frustrated people hitting validity errors and then giving up learning. The Zac Browser is an excellent example for autistic kids as is HTML for the web. Interfaces – both input and output – need to be able to evolve with skill level. I’ve written more over at DeWitt’s response to this in the comments if anyone’s interested.
June 8th, 2008 at 4:15 pm
Quick question; I know that many XSLT parsers actually parse the XML document into an in-memory representation and then work on that representation; they aren’t necessarily exposed to the XML, but rather to an abstraction of a tree. Some XSLT parsers can theoretically be passed ‘anything’ that can be represented as a tree, whether it was originally in XML or not at the beginning. If HTML 5 has well-defined parsing rules, and can pass you back a tree, why couldn’t you apply XSLT on to that tree, or XPath for that matter? I know there will probably be issues with XML namespaces in that situation, however, but I’m sure there are solutions.
Is this a viable option for getting the functionality of XSLT and XPath along with HTML 5? It reminds me a bit of how Firefox can apply an XPath expression on to the visible DOM, even if it is a messy HTML document since the document has already been parsed into a tree representation and the XPath can just use the nice, in-memory representation.
Best,
Brad Neuberg
June 9th, 2008 at 12:33 am
Yes, you can use XSLT with HTML5. In fact, the sample code that comes with the Validator.nu HTML parser shows how to use XSLT on HTML5.
June 9th, 2008 at 1:40 am
Elliotte,
thanks for answering. I would still argue though, because I don’t agree with the statement that “text/html is just fine if it helps”. I’m sorry, but it’s not fine. I have to repeat myself – IE doesn’t support true XHTML at all (and I wouldn’t count on it supporting it in the near future).
Given that unfortunately IE still holds from 50 to 80% of the browser market (depending on the region of the world) that’s an issue you can’t ignore. And contrary to what you suggest, it’s not ok to have a XHTML webpage and serve it as application/xml+xhtml or text/html depending on what the UA accepts. The reason for that is there are some significant differences in rendering (for instance, the XML declaration will trigger quirks mode in IE6 when served as text/html – ruining the rendering). You can read a warning against using dual-mime on Mozilla Web Authoring FAQ as well.
June 9th, 2008 at 8:06 am
Funny, I serve XHTML off many pages (including this one) and my statistics show I get a reasonable number of visits from IE users. Clearly IE supports XHTML to some degree. (Like most questions this is not binary: the issue is how much it supports it, not whether it supports it.)
I do recommend not using an XML declaration on XHTML pages because it causes lots of problems for older browsers. However the XML declaration is in no way required for XHTML.
And the warning you cite simply says that there’s not a strong reason to serve XHTML to Mozilla as application/xhtml+xml. If you want to just serve it to Mozilla too as text/html, go right ahead. It does say that you shouldn’t serve application/xhtml+xml to Mozilla unless you’re sure it’s well-formed. That’s reasonable. After all, if it isn’t well-formed, then it isn’t XHTML. But if you are maintaining well-formedness, and you feel like being pedantic, then serve application/xhtml+xml to Mozilla and text/html to IE. Nothing significant breaks.
June 9th, 2008 at 9:06 am
Brad, yes that works. http://about.validator.nu/htmlparser/ has sample applications available.
June 9th, 2008 at 9:07 am
(Oops, seems Henri already replied. Sorry about that. Didn’t think new comments might have been posted meanwhile.)
June 9th, 2008 at 9:41 am
Right, I noticed now that you are serving this page as XHTML 1.0 Transitional (that is odd by the way, why Transitional?) but it does not validate – there is an error ‘document type does not allow element “style” here’.
Clearly, the page is parsed as text/html and that’s the only reason it’s readable and not showing a “XML parsing error” message. So what you wrote – “Nothing significant breaks” – is true only because you’re actually not using XHTML (like in serving this page as application/xhtml+xml, as it should be).
June 9th, 2008 at 10:04 am
And I repeat: that this page is served as text/html does not mean it is not XHTML. It is XHTML because it is well-formed markup in the correct namespace. Except for one funky bit that’s pulled in by one of the ads, it’s even valid.
The MIME type is not what one consults to determine if a page is or is not XHTML. I could label this page audio/mp3 and it would still be XHTML. Do not confuse the name or label of a thing with the thing itself.
I suggested one should publish XHTML. I did not suggest that one should label that XHTML with the MIME type application/xhtml+xml. That is your claim, not mine.
June 10th, 2008 at 6:41 pm
Responding to:
Anne van Kesteren
”
Igor, it shows you haven’t invested much in reading up what’s happening with mobile browsers. There’s actually very few of them which get XHTML right. Most have a forgiving HTML parser so they can render the Web. Now that we see more and more Opera and WebKit on mobile phones (and soon maybe Gecko powered too) they’ll just have the same capabilities as desktop browsers. As Ian already said, parsers are hardly the complicated bit.
”
Most phones don’t have an html browser at all, but most phones support XHTML MP. Admittedly many don’t “Get it right.”, there are many quirky phone browsers. But again, most phones don’t support html.
October 14th, 2008 at 2:22 pm
Brodie Rao Says:
June 5th, 2008 at 4:58 pm
“I’m sorry, but almost none of these points are relevant. If you’re trying to make a case to vendors that XHTML is better because it’s simpler, that’s not true at all. It’s just one more technology to support – HTML is never going away. However, that doesn’t matter to web developers and authors.”
I must agree here, There is a use for both of these formats and I don’t think they will ever both go away.
July 16th, 2015 at 4:18 am
I have been exploring for a little for any high quality articles or weblog posts on this sort of house .
Exploring iin Yahoo I eventually stumbled upon this site.
Studying this information So i’m glad to exhibit that I’ve a very good uncanny feeling I discovered just what I needed.
I such a lot undoubtedly will make sure to do not disregard this site and give it a glance on a continuing basis.
July 22nd, 2015 at 10:05 pm
wonderful issues altogether, you just gained a new reader.
What could you recommend in regards to your submit that you simply made
a few days in the past? Any certain?