Chapter 3: Well-formedness
Here’s part 15 of the ongoing serialization of Refactoring HTML, also available from Amazon and Safari.
The very first step in moving markup into modern form is to make it well-formed. Well-formedness is the basis of the huge and incredibly powerful XML tool chain. Well-formedness guarantees a single unique tree structure for the document that can be operated on by the DOM, thus making it the basis of reliable, cross-browser JavaScript. The very first thing you need to do is make your pages well-formed.
Validity, although important, is not nearly as crucial as well-formedness. There are often good reasons to compromise on validity. In fact, I often deliberately publish invalid pages. If I need an element the DTD doesn’t allow, I put it in. It won’t hurt anything because browsers ignore elements they don’t understand. If I have a blockquote that contains raw text but no elements, no great harm is done. If I use an HTML 5 element such as m that Opera recognizes and other browsers don’t, those other browsers will just ignore it. However, if the page is malformed, the consequences are much more severe.
First, I won’t be able to use any XML tools, such as XSLT or SAX, to process the page. Indeed, almost the only thing I can do with it is view it in a browser. It is very hard to do any reliable automated processing or testing with a malformed page.
Second, browser display becomes much more unpredictable. Different browsers fill in the missing pieces and correct the mistakes of malformed pages in different ways. Writing cross-platform JavaScript or CSS is hard enough without worrying about what tree each browser will construct from ambiguous HTML. Making the page well-formed makes it a lot more likely that I can make it behave as I like across a wide range of browsers.
What Is Well-formedness?
Well-formedness is a concept that comes from XML. Technically, it means that a document adheres to certain rigid constraints, such as every start-tag has a matching end-tag, elements must begin and end in the same parent element, and every entity reference is defined.
Classic HTML is based on SGML, which allows a lot more leeway than does XML. For example, in HTML and SGML, it’s perfectly OK to have a <br> or <li> tag with no corresponding </br> and </li> tags. However, this is no longer allowed in a well-formed document.
Well-formedness ensures that every conforming processor treats the document in the same way at a low level. For example, consider this malformed fragment:
<p>The quick <strong>brown fox</p> jumped over the <p>lazy</strong> dog.</p>
The strong element begins in one paragraph and ends in the next. Different browsers can and do build different internal representations of this text. For example, Firefox and Safari fill in the missing start- and end-tags (including those between the paragraphs). In essence, they treat the preceding fragment as equivalent to this markup:
<p>The quick <strong>brown fox</strong></p> <strong>jumped over the </strong> <p><strong>lazy</strong> dog.</p>
This creates the tree shown in Figure 3.1.
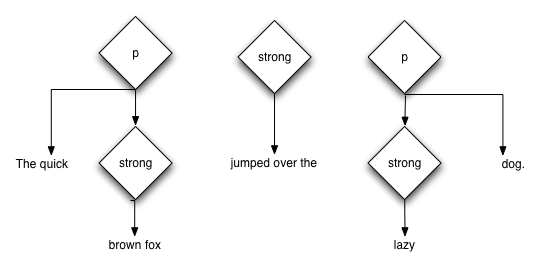
Figure 3.1: An overlapping tree as interpreted by Firefox and Safari
By contrast, Opera places the second p element inside the strong element which is inside the first p element. In essence the Opera DOM treats the fragment as equivalent to this markup:
<p>The quick <strong>brown fox jumped over the <p>lazy dog.</p> </strong> </p>
This builds the tree shown in Figure 3.2.
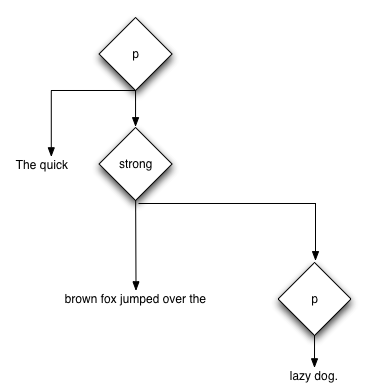
Figure 3.2: An overlapping tree as interpreted by Opera
If you’ve ever struggled with writing JavaScript code that works the same across browsers, you know how annoying these cross-browser idiosyncrasies can be.
By contrast, a well-formed document removes the ambiguity by requiring all the end-tags to be filled in and all the elements to have a single unique parent. Here is the well-formed markup corresponding to the preceding code:
<p>…foo<strong>…</strong></p> <p><strong>…bar</strong> </p>
This leaves no room for browser interpretation. All modern browsers build the same tree structure from this well-formed markup. They may still differ in which methods they provide in their respective DOMs, and in other aspects of behavior, but at least they can agree on what’s in the HTML document. That’s a huge step forward.
Anything that operates on an HTML document, be it a browser, a CSS stylesheet, an XSL transformation, a JavaScript program, or something else, will have an easier time working with a well-formed document than the malformed alternative. For many use cases such as XSLT, this may be critical. An XSLT processor will simply refuse to operate on malformed input. You must make the document well-formed before you can apply an XSLT stylesheet to it.
Most web sites will need to make at least some and possibly all of the following fixes to become well-formed.
- Every start-tag must have a matching end-tag.
- Empty elements should use the empty-element tag syntax.
- Every attribute must have a value.
- Every attribute value must be quoted.
- Every raw ampersand must be escaped as &.
- Every raw less-than sign must be escaped as <.
- There must be a single root element.
- Every nonpredefined entity reference must be declared in the DTD.
In addition, namespace well-formedness requires that you add an xmlns="http://www.w3.org/1999/xhtml" attribute to the root html element.
Although it’s easy to find and fix some of these problems manually, you’re unlikely to catch all of them without help. As discussed in the preceding chapter, you can use xmllint or other validators to check for well-formedness. For example:
$ xmllint --noout --loaddtd http://www.aw.com http://www.aw-bc.com/:118: parser error : Specification mandate value for attribute nowrap <TD class="headerBg" bgcolor="#004F99" nowrap align="left"> ^ http://www.aw-bc.com/:118: parser error : attributes construct error <TD class="headerBg" bgcolor="#004F99" nowrap align="left"> ^ http://www.aw-bc.com/:118: parser error : Couldn't find end of Start-tag TD line 118 <TD class="headerBg" bgcolor="#004F99" nowrap align="left"> ^ …
TagSoup or Tidy can handle many of the necessary fixes automatically. However, they don’t always guess right, so it pays to at least spot-check some of the problems manually before fixing them. Usually it’s simplest to fix as many broad classes of errors as possible. Then run xmllint again to see what you’ve missed.
The following sections discuss the mechanics and trade-offs of each of these changes, as they usually apply in HTML.
