February 12th, 2012
I was watching Gilbert Strang’s 18th lecture in 18.06 Linear Algebra a couple of days ago, and he laid out a theory of determinants that started from a few basic properties and derived all the usual results. However he provided essentially no motivation for what he was doing. Why these properties? How did any one ever think of these particular axioms? And more tellingly, what is a determinant, really? I don’t mean the official definition (here quoted from Wikipedia and similar to Strang’s):
If we write an n-by-n matrix in terms of its column vectors
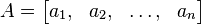
where the aj are vectors of size n, then the determinant of A is defined so that



where b and c are scalars, v is any vector of size n and I is the identity matrix of size n. These properties state that the determinant is an alternating multilinear function of the columns, and they suffice to uniquely calculate the determinant of any square matrix. Provided the underlying scalars form a field (more generally, a commutative ring with unity), the definition below shows that such a function exists, and it can be shown to be unique.
I can follow the derivation from that, but it doesn’t really explain what a determinant is. And the only alternative I could find in Wikipedia or the readily available textbooks, was that it’s the volume of a parallelepiped of the matrix formed by the vectors representing the parallelepiped’s sides. Again, that feels like a derived property, not a true definition. However, Mathworld, did give me one big hint:
For example, eliminating x, y, and z from the equations
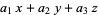 = 0
= 0
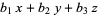 = 0
= 0
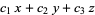 = 0
= 0
gives the expression
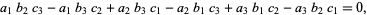
which is called the determinant for this system of equation.
So here’s the answer: the determinant is the condition under which a set of linear equations has a non-trivial null space. Or, more simply, the determinant is the condition on the coefficients a, b, c… of a set of n linear equations in n unknowns such that they can be solved for the right hand side (0, 0, 0, …0) where at least one of the unknowns (x, y, …) is not zero. Let me prove that:
Read the rest of this entry »
Posted in Math | 4 Comments »
January 19th, 2012
Dear Librarians,
I’d like to thank you for the work you’ve done putting the library catalog online. The ability to reserve books online (and then renew them online when I don’t finish them on time) has been invaluable. It has dramatically increased my use of the library. Now when I need a book I routinely check the library first rather than ordering it from Amazon. It’s cheaper, the book gets to me faster; and when I’m done, the book no longer takes up space in my apartment. Excellent! Kudos all around.
And now you have eBooks so I don’t even have to go to the library to pick up my reservations! Regrettably the selection of eBooks is somewhat thinner and more oversubscribed; and yes, I know this is partially the publishers’ fault. Still, for the books that are available, it’s wonderful knowing that even the thickest physics text or mathematical tome isn’t going to weigh more than a small eReader or tablet. It makes reviewing calculus on the subway so much more practical.
I’d like to make a friendly suggestion for ramping this up a notch, making the library even more useful, expanding the collection, and increasing monetary donations to the library at the same time. Your circulating collection is large, probably one of the largest in the country, and certainly the largest one I’ve ever had the pleasure to use. Probably 90% of the time the book I’m looking for is available at one of your branches, and you helpfully bring it from wherever it is to my local library where I can pick it up off the reserve shelf. But there’s still that 10% of the time when you happen not to have the book I’m looking for. (And for eBooks that’s more like 90% of the time.) Sometimes that’s because it’s a relatively obscure technical book; but sometimes it just looks like a fluke. For instance, it’s the second book in a trilogy for which you have the first and the third, but somehow missed the middle (or it went missing). Or it’s a novel by an author, most of whose works you already have. It’s something that clearly fits in your collection but just doesn’t happen to be there yet. So off I surf to Amazon where I buy a book I only really want to read once, and that then is going to sit on my shelf untouched for years.
Here’s my idea: I’d rather buy the book for the library and than buy it for myself.
Read the rest of this entry »
Posted in Internet | 7 Comments »
September 29th, 2011
So after reading this poll of mathematicians and computer scientists who have given the problem way more thought than I have, I now suspect that indeed P == NP (though perhaps not usefully so). Why do I think this?
Read the rest of this entry »
Posted in Math | 4 Comments »
January 1st, 2011
In 2011 my New Year’s resolution is to do more things the easy way, even if it takes longer the first time. I am going to stop using brute force to solve problems. In particular:
- I am finally going to memorize how one redirects both stderr and stdout to the same stream. (
2>&1 |)
- I am going to learn the sed? trick my advisor showed me 20 years ago for repeating a command from the shell history while substituting one word for another, instead of just using the arrow key to backup to and erase the string. (
^string1^string2^ or !!:s/string1/string2/ or for global substitution, not just the first occurrence !!:gs/string1/string2/)
- I am going to increase my regex fu and use regular expressions consistently instead of just editing 20 lines of copy and paste code. (This would be easier if every editor didn’t have subtly different syntax.)
- I am going to use Python to automate repetitive tasks.
Posted in Programming | 5 Comments »
December 4th, 2010
First for the record, I’m speaking only for myself, not my employer, the W3C, Apple, Google, Microsoft, WWWAC, the DNRC, the NFL, etc.
XML 1.1 failed. Why? It broke compatibility with XML 1.0 while not offering anyone any features they needed or wanted. It was not synchronous with tools, parsers, or other specs like XML Schemas. This may not have been crippling had anyone actually wanted XML 1.1, but no one did. There was simply no reason for anyone to upgrade.
By contrast XML did succeed in replacing SGML because:
- It was compatible. It was a subset of SGML, not a superset or an incompatible intersection (aside from a couple of very minor technical points no one cared about in practice)
- It offered new features people actually wanted.
- It was simpler than what it replaced, not more complex.
- It put more information into the documents themselves. Documents were more self-contained. You no longer needed to parse a DTD before parsing a document.
To do better we have to fix these flaws. That is, XML 2.0 should be like XML 1.0 was to SGML, not like XML 1.1 was to XML 1.0. That is, it should be:
- Compatible with XML 1.0 without upgrading tools.
- Add new features lots of folks want (but without breaking backwards compatibility).
- Simpler and more efficient.
- Put more information into the documents themselves. You no longer need to parse a schema to find the types of elements.
These goals feel contradictory, but I plan to show they’re not and map out a path forward.
Read the rest of this entry »
Posted in XML | 48 Comments »
