Machine Learning Failure Modes
Yesterday I was reminded of a common failing in machine learning algorithms that again suggests they aren’t really thinking or understanding. Possibly it points to the lack of a world model. Here’s a nice little photo I caught of a bird in its environment:

Do you see the bird? Do you know what it is? (If you’re not a birder, I’ll give you a hint. It’s an American Kestrel.) This isn’t an especially tough or complicated ID once you spot the bird sitting on the pipe. I could have cropped it in closer, but I sort of liked the environment in this one.
And here’s what the rather good iNaturalist machine learning model suggested:
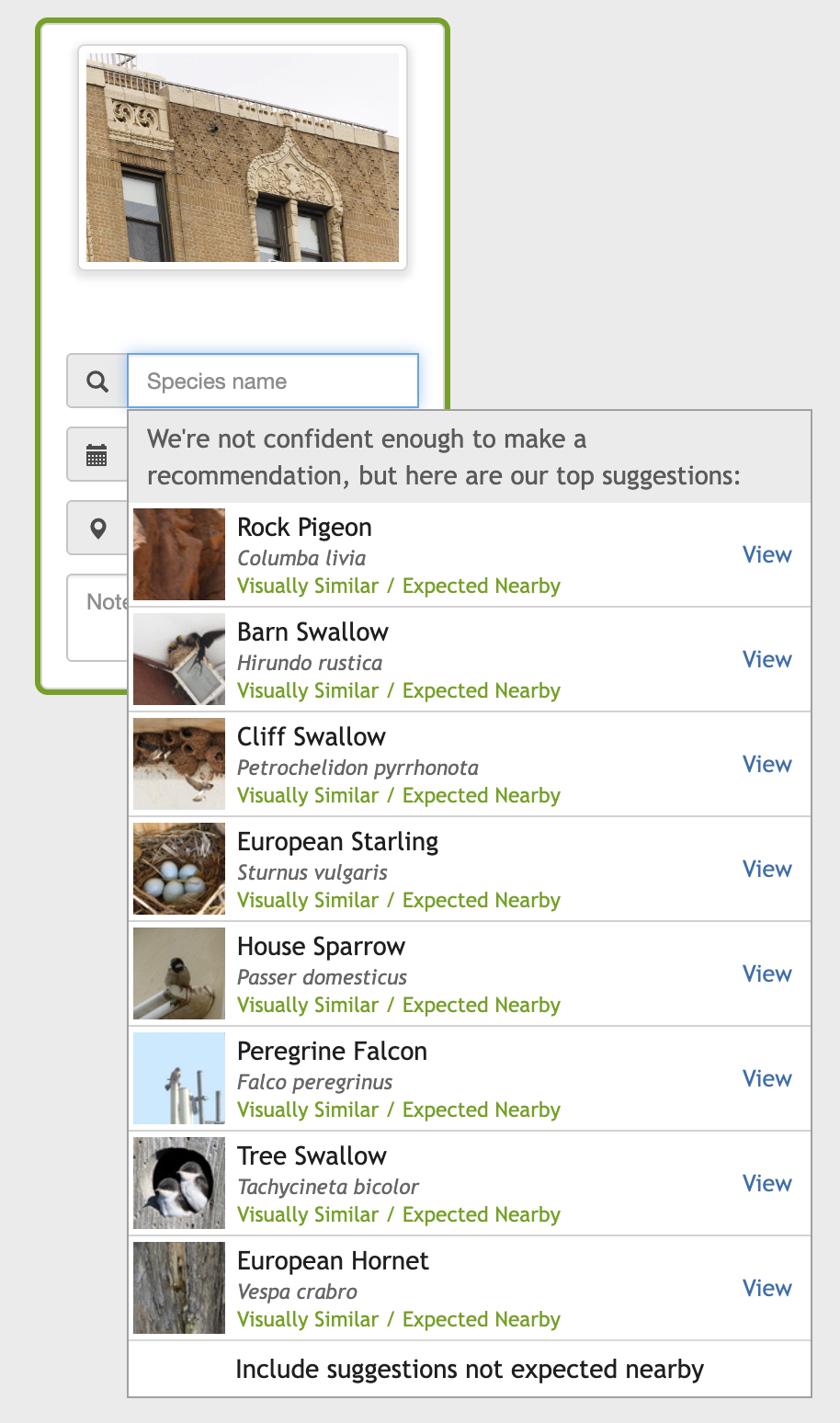
Peregrine Falcon isn’t too far off, but the rest are not even close. Clearly the ML model has missed the bird and is instead identifying the background. It’s suggesting species that are likely to be seen high up on buildings and walls. The failure mode is keying off features that are not particularly relevant.
They’re not completely irrelevant. Knowing that the bird is in an urban environment does massively cut down on the search space. Seeing that it’s perched on a building cuts it down a little more. But clearly the model has learned features from the backgrounds of photos as a fundamental part of the features of birds. That’s not ideal. I’ve also seen this in insect photos where concrete or dirt get picked up as the identifying characteristic. This is not a mistake an experienced human would make.
This isn’t to say the model is useless. It definitely isn’t. Indeed it can pick out some distinctions and make IDs humans didn’t think were possible. Notably the iNaturalist model can tell the difference between a Fish Crow and an American Crow from a good photograph about 90% of the time. Ornithologists thought you could only do this by call or careful measurement of collected specimens. Turns out that’s not the case. The model sees small differences in shape and relative feather length that are diagnostic, even if not necessarily observable in the moment on a wild bird with binoculars.
But the pattern recognition of the model is still limited compared to what a human can do. And the pattern recognition of a human is sometimes less observant than what a machine can do. Where to go with this? I don’t know. For now, I think we need both. I tend to doubt that simply adding more training data will improve the ML models all that much in cases like this, but perhaps there are other approaches that add non-deep-learning approaches to image recognition on top of the existing algorithms that might help.
